text.split
使用大模型进行翻译时,对翻译的文本会有以下担忧:
- 单次翻译的文本内容过长,会造成极大的延迟等待,影响用户体验
- 如果文本中包含一些特殊字符符号,容易使翻译结果只返回文本的翻译结果,而特殊符号会被大模型删除(特别是小模型)
- 文本过长及包含特殊符号,会导致大模型理解及指令遵循出现异常,翻译结果出现失误。
针对以上问题,可以通过配置自由对文本进行分割,将长句子分割为数个短句子或单词,然后分别对分割后的进行翻译。翻译好后再进行组合。
配置方式
# 对翻译的内容进行分割的字符,比如 "你好?是的" 会分割为 "你好?" "是的" 两个翻译文本# 参数设置说明:# string 要进行分割的字符,比如 ?# 另外,这个有几个特殊意义的标识,这几个标识中,translate 配置将不生效,都是程序里单独匹配处理的,如果出现这种标识,就针对性处理,如果不出现,就不针对性处理:# [english.] 针对非中文场景,需要连字符的句号,进行分割。这里主要针对英文进行的适配, 英文字母+.+1个或多个空格+英文字母 ,只有这种情况的才会去处理拆分# [url] 针对url进行拆分处理,将url部分过滤掉,不翻译url,只保留拆分后的非url的文本# [filename] 针对文件名进行拆分处理,将文件名部分过滤掉,不翻译文件名,只保留拆分后的非文件名的文本。比如 abc-def.png 这种文件名# [email] 针对邮箱进行拆分处理,将邮箱部分过滤掉,不翻译邮箱,只保留拆分后的非文件名的文本。比如 abc@12.com 这种邮箱# [htmltag] 针对有html标签的,过滤掉html标签不被翻译 ## translate 进行分割的字符是否参与翻译。 比如问号,叹号这种语气词,加上会能影响语义的,就要设置为true; 而像是换行符这种并不影响语义的,那就设置为false。 设置为false后使翻译的文本更少,翻译的效果更好。 # 比如 "你好?是的" # 设置为true时,会分割为 "你好?" "是的" 两个翻译文本,进行分别翻译。 翻译完组合后,结果为 "hello? yes"# 设置为false时,会分割为 "你好" "是的" 两个翻译文本,进行分别翻译。并且 "你好" 翻译完成后,再追加上 "?" 这个文本,并组合为 "hello?" 作为它的翻译结果。 也就是翻译结果为 "hello? yes"# 更详细说明可参考 http://translate.zvo.cn/472865.html#text.split=[{"string":"u005cu006e","translate":false,"remark":"换行符"},{"string":"u005cu0074","translate":false,"remark":"缩进符"},{"string":"u005cu0072","translate":false,"remark":"换行符"},{"string":"uff1f","translate":true,"remark":"?"},{"string":"u3002","translate":true,"remark":"。"},{"string":"uff1b","translate":false,"remark":";"},{"string":"uff01","translate":true,"remark":"!"},{"string":"uff1a","translate":false,"remark":":"},{"string":"[","translate":false,"remark":"["},{"string":"]","translate":false,"remark":"]"},{"string":"|","translate":false,"remark":"|"},{"string":"_","translate":false,"remark":"_"},{"string":"*","translate":false,"remark":"*"},{"string":"[english.]","remark":"英文句号"},{"string":"[url]","remark":"网址过滤"},{"string":"[email]","remark":"邮箱过滤"},{"string":"[filename]","remark":"文件名过滤"},{"string":"[htmltag]","remark":"html标签过滤"}]# 如果进行翻译的文本被拆分了,是否打印出拆分的日志。 true:显示日志。 默认不设置则是false。 此处是方便对 text.split 定义的进行调试查看使用#text.split.debug=true
如果默认不配置 text.split 参数,那么它的默认值为:
[{"string":"u005cu006e","translate":false,"remark":"n"},{"string":"u005cu0074","translate":false,"remark":"t"},{"string":"u005cu0072","translate":false,"remark":"r"},{"string":"uff1f","translate":true,"remark":"?"},{"string":"u3002","translate":true,"remark":"。"},{"string":"uff1b","translate":false,"remark":";"},{"string":"uff01","translate":true,"remark":"!"}]
日志查看
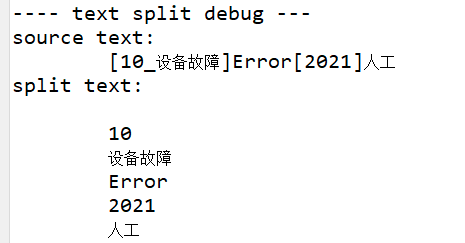
开启 text.split.debug=true 后,如果句子中包含了 text.split 的分割字符,那么分割后会自动打印分割日志到 /mnt/service/translate.service.log 日志文件,如下图:
使用大模型进行翻译时,对翻译的文本会有以下担忧:
- 单次翻译的文本内容过长,会造成极大的延迟等待,影响用户体验
- 如果文本中包含一些特殊字符符号,容易使翻译结果只返回文本的翻译结果,而特殊符号会被大模型删除(特别是小模型)
- 文本过长及包含特殊符号,会导致大模型理解及指令遵循出现异常,翻译结果出现失误。
针对以上问题,可以通过配置自由对文本进行分割,将长句子分割为数个短句子或单词,然后分别对分割后的进行翻译。翻译好后再进行组合。
## 配置方式
```properties
# 对翻译的内容进行分割的字符,比如 "你好?是的" 会分割为 "你好?" "是的" 两个翻译文本
# 参数设置说明:
# string 要进行分割的字符,比如 ?
# 另外,这个有几个特殊意义的标识,这几个标识中,translate 配置将不生效,都是程序里单独匹配处理的,如果出现这种标识,就针对性处理,如果不出现,就不针对性处理:
# [english.] 针对非中文场景,需要连字符的句号,进行分割。这里主要针对英文进行的适配, 英文字母+.+1个或多个空格+英文字母 ,只有这种情况的才会去处理拆分
# [url] 针对url进行拆分处理,将url部分过滤掉,不翻译url,只保留拆分后的非url的文本
# [filename] 针对文件名进行拆分处理,将文件名部分过滤掉,不翻译文件名,只保留拆分后的非文件名的文本。比如 abc-def.png 这种文件名
# [email] 针对邮箱进行拆分处理,将邮箱部分过滤掉,不翻译邮箱,只保留拆分后的非文件名的文本。比如 abc@12.com 这种邮箱
# [htmltag] 针对有html标签的,过滤掉html标签不被翻译
#
# translate 进行分割的字符是否参与翻译。 比如问号,叹号这种语气词,加上会能影响语义的,就要设置为true; 而像是换行符这种并不影响语义的,那就设置为false。 设置为false后使翻译的文本更少,翻译的效果更好。
# 比如 "你好?是的"
# 设置为true时,会分割为 "你好?" "是的" 两个翻译文本,进行分别翻译。 翻译完组合后,结果为 "hello? yes"
# 设置为false时,会分割为 "你好" "是的" 两个翻译文本,进行分别翻译。并且 "你好" 翻译完成后,再追加上 "?" 这个文本,并组合为 "hello?" 作为它的翻译结果。 也就是翻译结果为 "hello? yes"
# 更详细说明可参考 http://translate.zvo.cn/472865.html
#text.split=[{"string":"u005cu006e","translate":false,"remark":"换行符"},{"string":"u005cu0074","translate":false,"remark":"缩进符"},{"string":"u005cu0072","translate":false,"remark":"换行符"},{"string":"uff1f","translate":true,"remark":"?"},{"string":"u3002","translate":true,"remark":"。"},{"string":"uff1b","translate":false,"remark":";"},{"string":"uff01","translate":true,"remark":"!"},{"string":"uff1a","translate":false,"remark":":"},{"string":"[","translate":false,"remark":"["},{"string":"]","translate":false,"remark":"]"},{"string":"|","translate":false,"remark":"|"},{"string":"_","translate":false,"remark":"_"},{"string":"*","translate":false,"remark":"*"},{"string":"[english.]","remark":"英文句号"},{"string":"[url]","remark":"网址过滤"},{"string":"[email]","remark":"邮箱过滤"},{"string":"[filename]","remark":"文件名过滤"},{"string":"[htmltag]","remark":"html标签过滤"}]
# 如果进行翻译的文本被拆分了,是否打印出拆分的日志。 true:显示日志。 默认不设置则是false。 此处是方便对 text.split 定义的进行调试查看使用
#text.split.debug=true
```
如果默认不配置 text.split 参数,那么它的默认值为:
```json
[{"string":"u005cu006e","translate":false,"remark":"n"},{"string":"u005cu0074","translate":false,"remark":"t"},{"string":"u005cu0072","translate":false,"remark":"r"},{"string":"uff1f","translate":true,"remark":"?"},{"string":"u3002","translate":true,"remark":"。"},{"string":"uff1b","translate":false,"remark":";"},{"string":"uff01","translate":true,"remark":"!"}]
```
## 日志查看
开启 `text.split.debug=true` 后,如果句子中包含了 text.split 的分割字符,那么分割后会自动打印分割日志到 /mnt/service/translate.service.log 日志文件,如下图:
